How approval-gated deployments, rollback policy design, and audit evidence reduce failed production releases and speed incident recovery.
Most release incidents we investigated followed the same pattern: the change itself was valid, but the release process failed under pressure. Deploys were started without clear ownership, production checks were skipped during urgent windows, and rollback instructions existed in documents but not in executable policy.
Before introducing approval gates, production deployments were effectively controlled by whoever had enough access and urgency. During normal days this felt fast. During high-risk changes it created ambiguity: was this rollout reviewed, is this the right artifact, and who is accountable for the go decision.

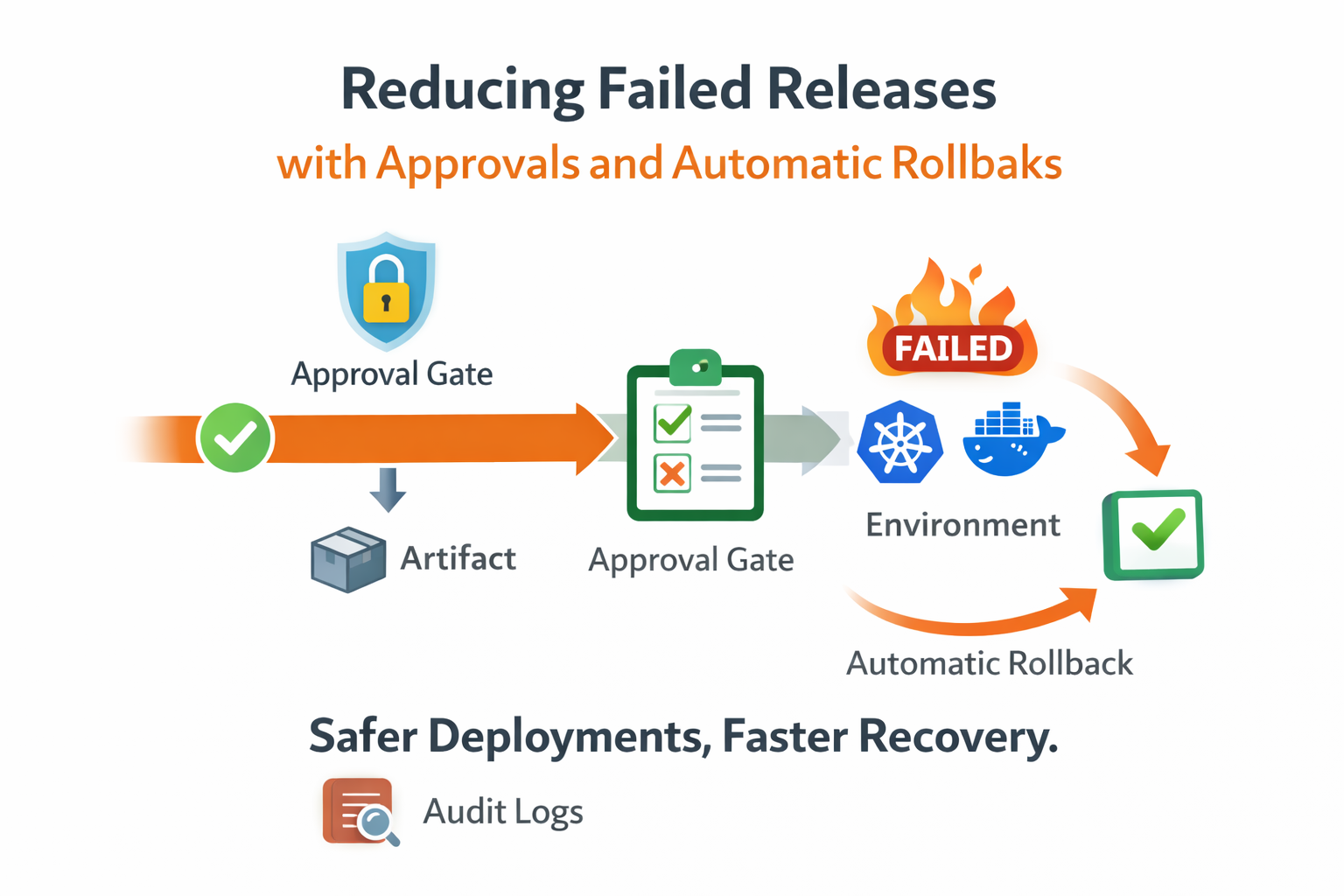
We designed approvals as a release-level control, not a manual chat step. A release can be prepared fully with selected source, artifact, environments, and inputs, but execution stays in pending approval until authorized users approve. This separated preparation from authorization and removed accidental early execution.
The first benefit was behavioral consistency. Teams stopped using side-channel approvals in chat and started reviewing the same release context every time. Approvers looked at concrete metadata: selected tag, release file, target environments, launch inputs, and linked blueprint behavior. Review quality improved because context was no longer fragmented.
The second benefit was timing control. Approvals gave us a clean wait state for planned deploy windows. Releases could be created in advance and executed only when on-call and stakeholders were ready. This reduced rushed edits and removed last-minute reconfiguration directly in runner hosts.
Rollback policy completed the safety model. We attached rollback rules during release creation: trigger target (full pipeline or critical job), delay window, and rollback source mode. Instead of improvising shell commands after failure, the platform created a linked rollback release with full traceability.
rollback:
enabled: true
check_target: critical_healthcheck
delay_seconds: 120
mode: last_successfulIn practice, automatic rollback was most effective when tied to one authoritative post-deploy health gate. If that gate failed, rollback triggered after a short delay. Teams used that delay to confirm signal quality and prevent false positives while still keeping recovery fast when failure was real.
This approach changed incident response dynamics. Operators no longer debated which old command to run first. They inspected the failed run, validated blast radius, and followed a known recovery path already attached to the release. Decision latency dropped because the process was predefined.
Audit logs made the governance part measurable. Every approval, cancellation, rerun, and rollback event was stored with actor and timestamp. Postmortems became concrete: we could reconstruct exactly when approval happened, when execution started, where it failed, and when rollback completed.
One important lesson was scope discipline. We avoided overloading approvals for low-risk environments. Non-production stayed fast with lightweight policies, while production used stricter controls. This preserved delivery speed where risk was low and applied governance where failure cost was high.

After adopting approval-gated releases and policy-based rollback for critical services, failed production releases requiring manual recovery dropped materially. The larger win, however, was confidence: teams could move quickly because safety controls were embedded in the flow, not added during crisis.
If your releases still depend on manual coordination, start by enforcing one reliable gate: explicit approval on production plus a tested rollback mode. Once that path is stable and auditable, expand policy depth. Reliability usually improves faster from clear control points than from adding more scripts.
Key takeaways
- Pending approval prevents unreviewed production execution.
- Rollback can trigger from pipeline or critical job status.
- Audit trail keeps release decisions and actions attributable.