A practical self-hosted CI/CD guide to separating build pipelines from deployment orchestration without slowing team delivery.
For two years we ran a single "do everything" pipeline: build, test, package, deploy, post-check, and rollback scripts all in one CI definition. At first it looked efficient, but as environments and services grew, every release became harder to reason about. Small deployment changes required touching build logic, and build maintainers had to carry production risk decisions they did not own.
The operational symptoms were visible every week. Production rollouts waited behind unrelated build queue load. Teams repeated near-identical jobs just to move the same artifact from QA to staging and then to production. During incident calls, people opened multiple systems to reconstruct the release path because the CI run alone did not represent real approval and deployment intent.
We audited twelve failed or delayed releases across one quarter. In most cases, the root cause was not a bad binary. The failure came from process coupling: wrong runtime variable selected in CI, ad-hoc SSH fallback commands, missing approval evidence, or uncertainty about which artifact was actually promoted. Our conclusion was simple: CI gave us build automation, but we needed a deployment control plane.

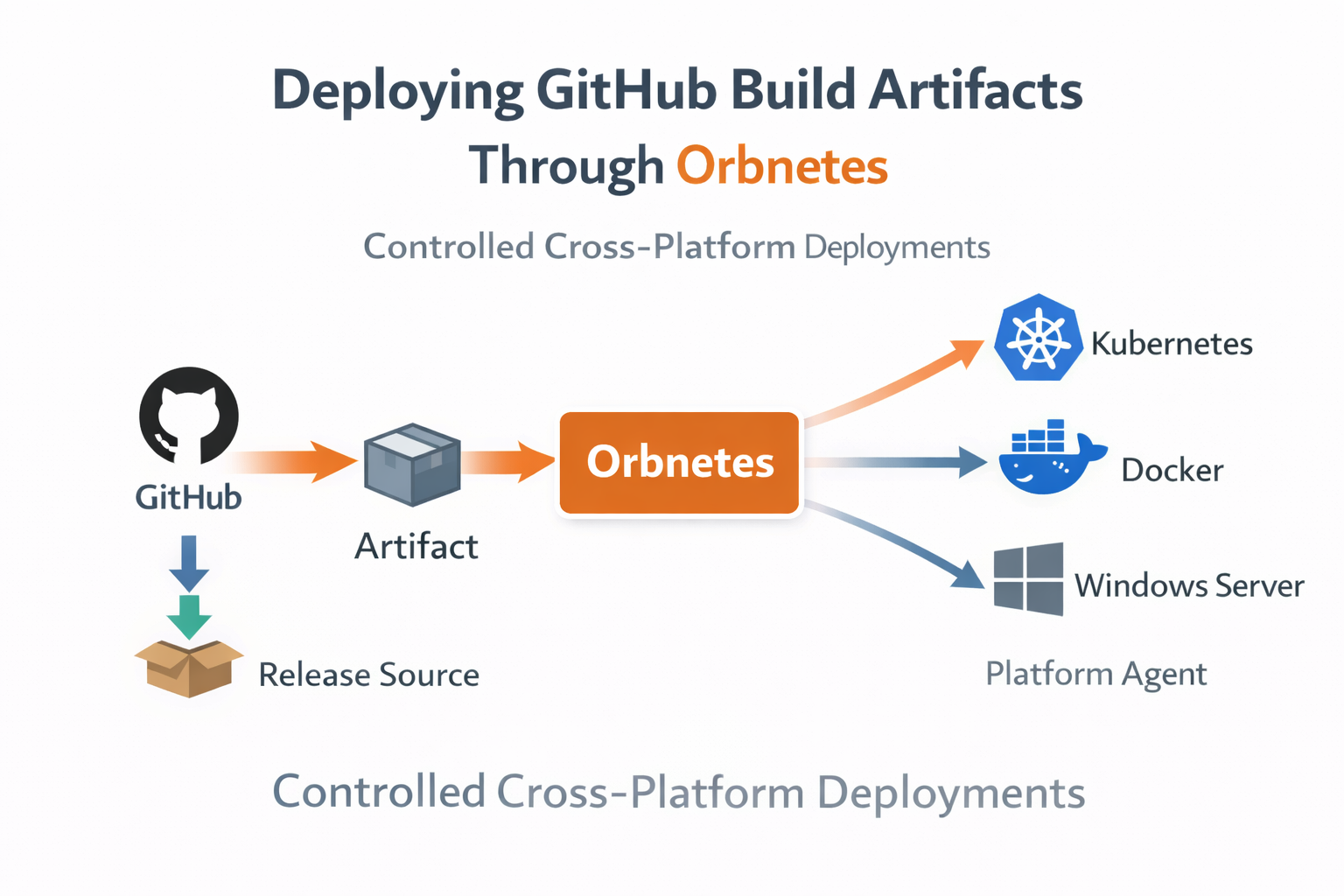
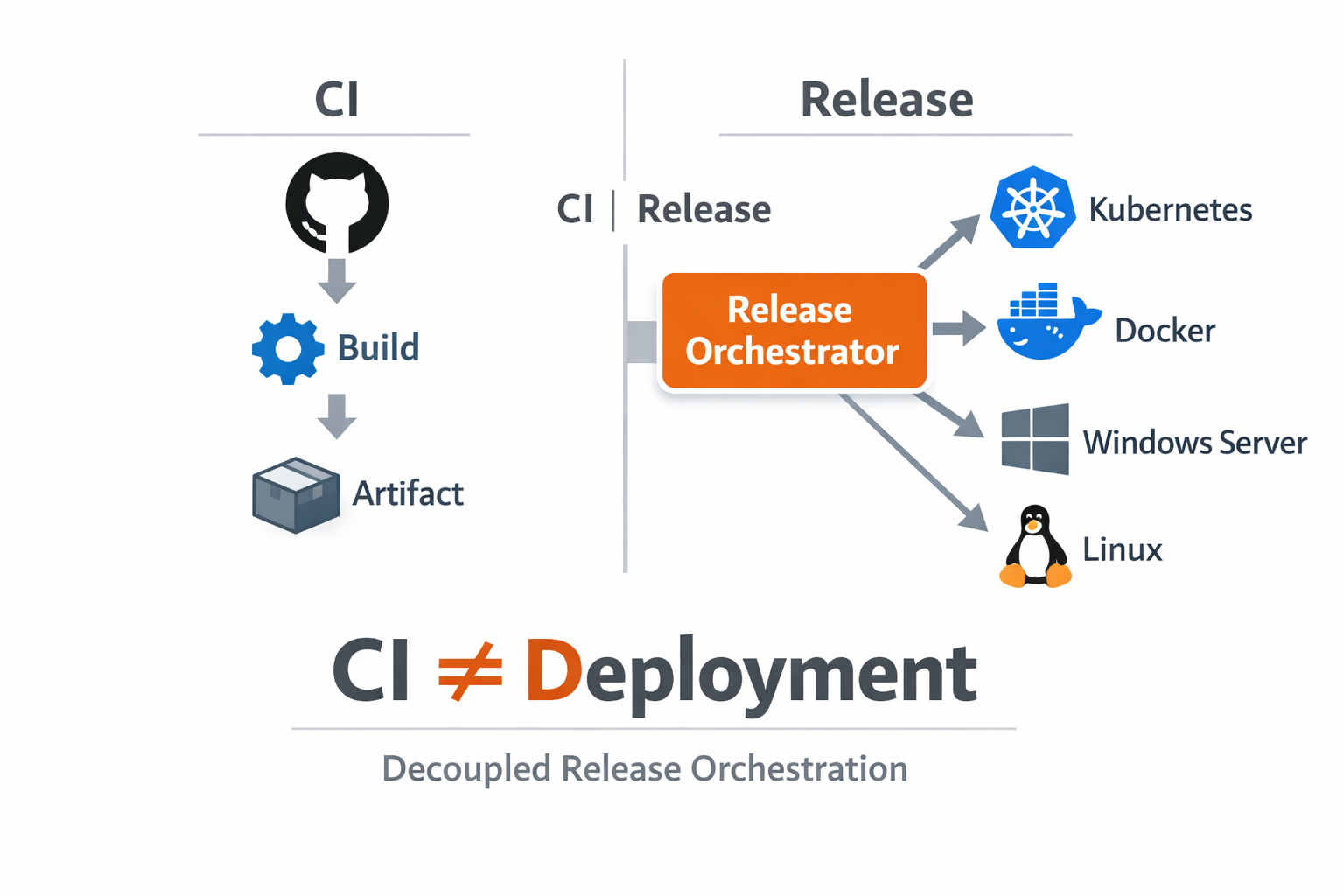
We split the flow into two explicit layers. CI remained responsible for compile, test, security scanning, and artifact publishing. Deployment moved into Orbnetes, where each release requires an explicit source, tag, file, blueprint, target environments, and optional approvers. This created a contract: build systems produce immutable outputs, and release orchestration governs when and where those outputs run.
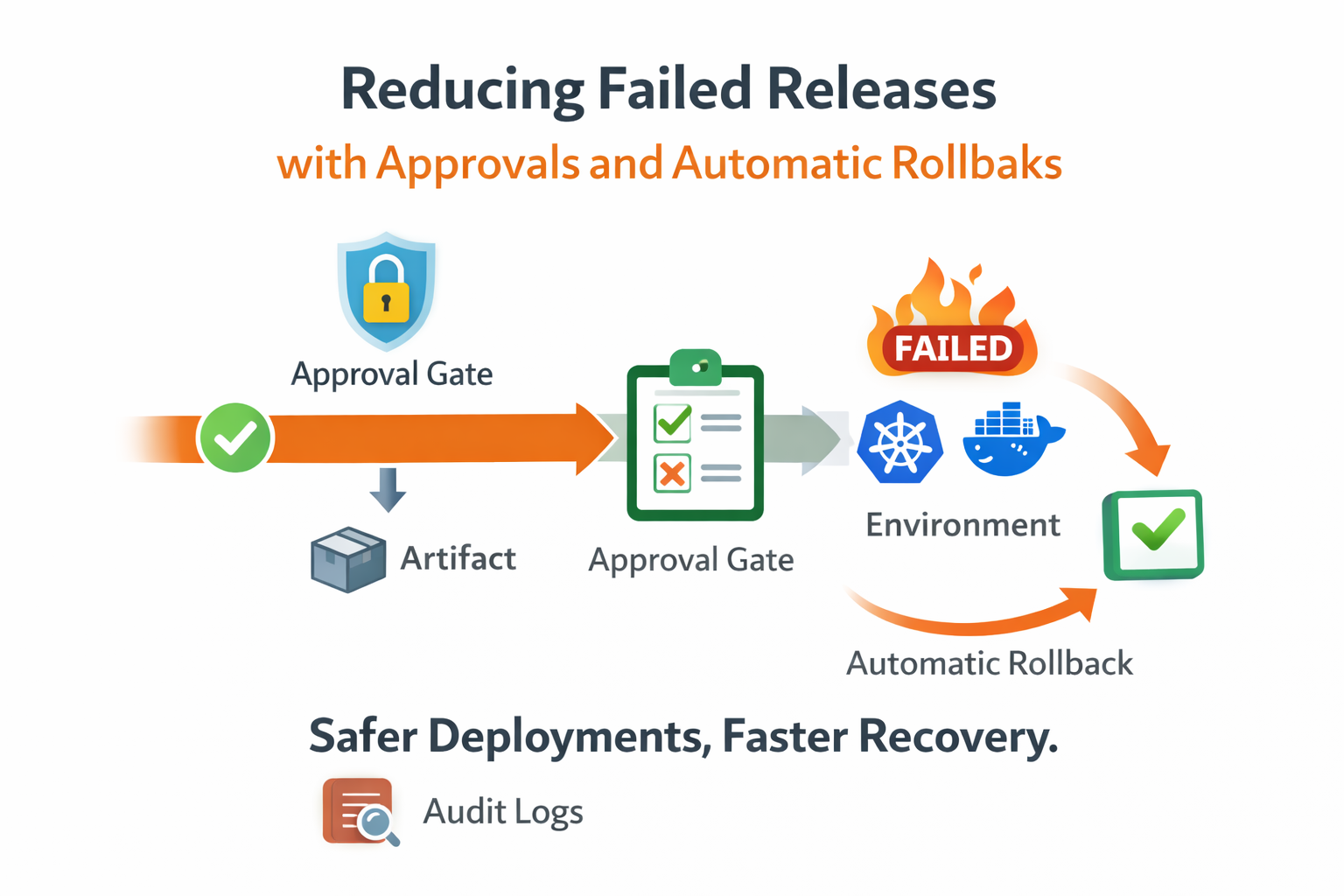
The migration started with one service and one non-production environment. We mapped the old CI deploy stage into a YAML blueprint with two jobs: backup and deploy. After validating agent routing and live logs, we added approval gates for production and a rollback policy tied to health-check status. Only after these controls were stable did we disable CI-driven production deploy jobs.
A key design rule was "build once, deploy many." The artifact produced in CI is immutable and referenced by source + tag + file at release time. Promotion from QA to staging to production no longer creates new builds. This removed artifact drift and made environment comparisons meaningful because every stage receives the same binary, not a best-effort rebuild.
We also separated responsibilities clearly. Developers still own build quality and blueprint logic in pull requests. Platform and operations teams own permission boundaries, approval policy, and environment-scoped runtime configuration. This eliminated ambiguous ownership during incidents: everyone knows where to investigate based on whether the issue is build-time, release-governance, or host-runtime.
The biggest operational improvement appeared in traceability. Every release now stores actor, timestamp, source metadata, selected artifact, inputs, environment targets, approval history, pipeline graph, and per-step logs. Instead of reading generic CI job output, we can answer concrete questions quickly: who approved production, which version was selected, what command failed first, and what rerun or rollback followed.
Recovery speed improved as well. Previously, after a failed deploy, teams often rebuilt or manually re-ran large CI stages. Now operators use rerun failed or trigger rollback from a known release context. Because execution evidence and dependencies are already visible in the graph, troubleshooting starts at the first failed step, not from scratch.
Security posture also became cleaner. Sensitive deploy credentials moved out of repository-level CI variables into scoped secrets managed by project and environment. Approval actions are permission-gated, and high-risk changes are auditable without parsing external tools. This reduced both accidental exposure risk and compliance effort for release evidence collection.
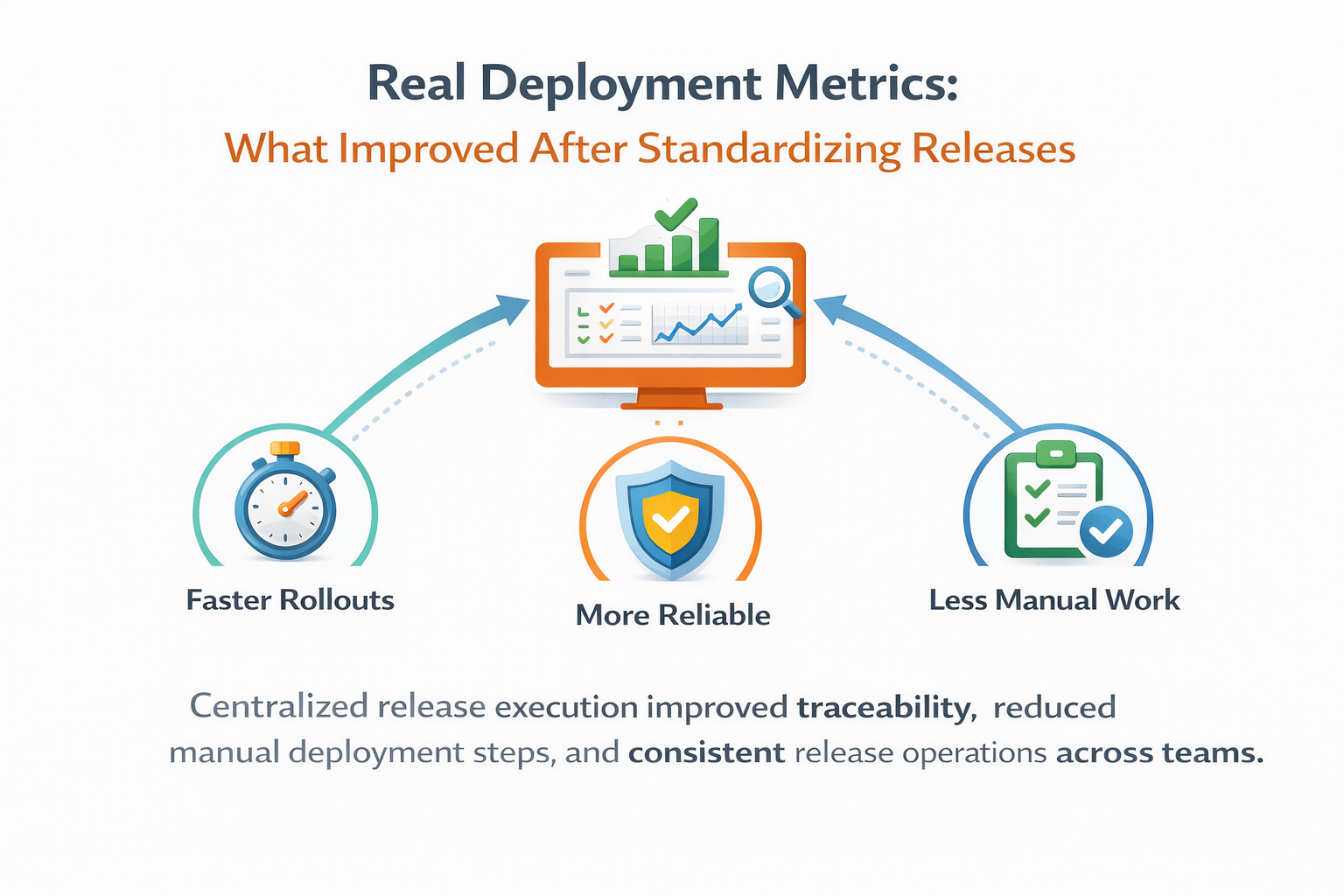
After three months, we compared metrics against the previous quarter. Median time from release creation to production completion dropped by 27%. Failed releases requiring manual intervention dropped by 34%. Mean time to identify first causal failure step during incidents dropped from 22 minutes to 9 minutes, mostly because graph + live logs provided immediate context.

Importantly, build throughput did not regress. CI remained fast because deployment-specific steps were removed from build pipelines. Teams stopped waiting for environment-specific deploy stages on every branch run, and build pipelines became easier to maintain because they returned to their original purpose: producing validated artifacts.
This architecture also scaled better across teams. Different services now reuse a common release model while keeping project-level isolation for permissions, agents, and config. New services onboard faster by starting from a blueprint template and connecting an existing artifact source, instead of duplicating complex CI deploy jobs from older repositories.
jobs:
deploy:
needs: [backup]
tags: [linux]
steps:
- name: deploy-release-file
shell: bash
run: |
echo "Deploying: $ORBN_RELEASE_FILE"
./deploy.sh "$ORBN_RELEASE_FILE"Our practical lesson is that speed and control are not opposites. Delivery slows down when control is implicit, fragmented, or hidden in scripts. Delivery speeds up when controls are explicit, repeatable, and attached to a clear execution model. Separating CI from deployment gave us both: stable build velocity and safer, more observable releases.
If your current pipeline mixes build responsibilities with production governance, start with one controlled slice: one service, one environment, one blueprint, one release source. Validate observability and ownership boundaries first, then expand. The payoff is cumulative, and it starts as soon as teams stop using build jobs as a surrogate deployment platform.
Key takeaways
- CI produces artifacts; release orchestration governs deployment.
- The same artifact is promoted across environments without rebuild.
- Approvals, audit, and rollback are explicit deployment controls.